Choosing how to store your strings
Introduction
When you work with strings in Julia you have several options how to store them. In this post I discuss the most common usage scenarios and the recommended choices.
The sting storage decision tree
The choices I discuss below are related to performance and memory consumption. Therefore in what follows I assume you work with large data sets relative to available RAM on your machine.
Let me start with the decision flowchart and then explain it:
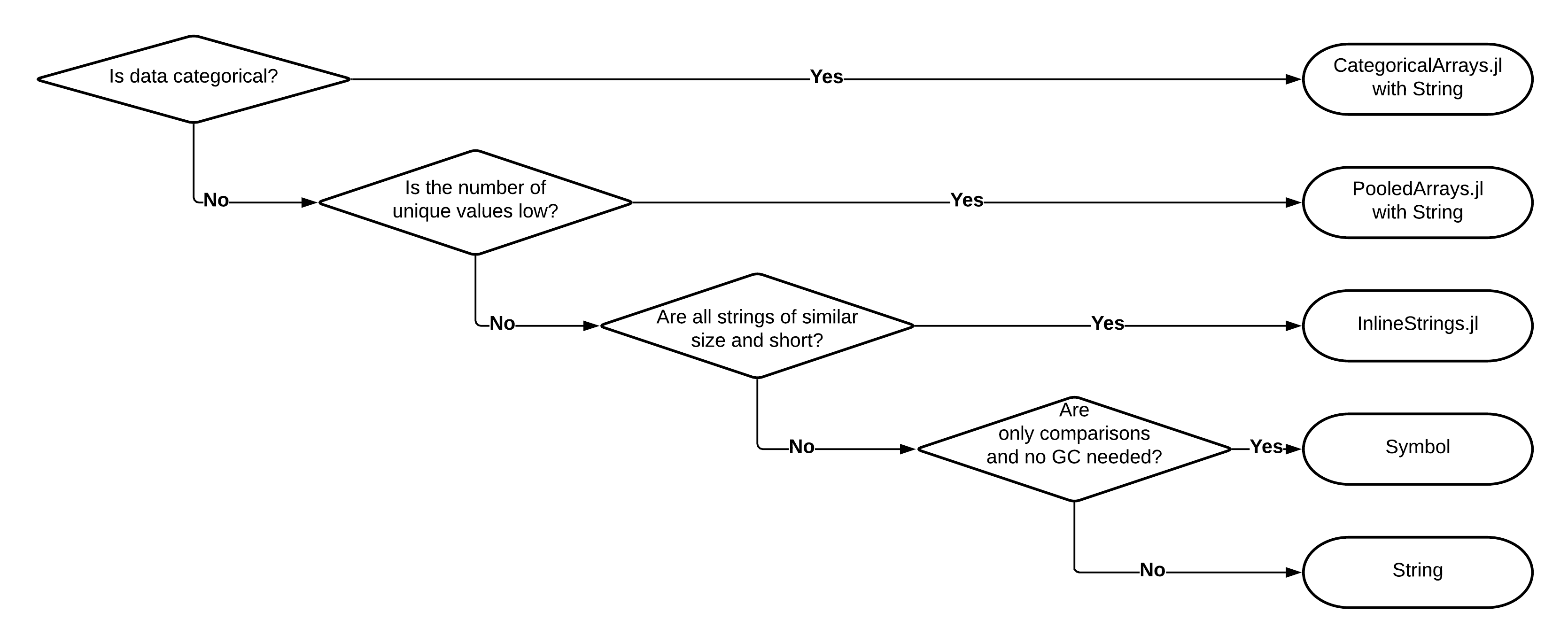
The first decision you need to make is if you want only performance optimization
or you want your strings to be treated as ordered or unordered categorical data
in statistical sense. If you need your data to be categorical then the choice
is simple. The only option is to use the CategoricalArrays.jl package,
where the underlying data can be stored in a String.
On the other hand if your goal is only performance and saving memory then the
first question is if the number of unique values of strings in your data is
low. If this is the case then the recommended package is PooledArrays.jl, where again you should be fine with storing String values.
We are down to the scenario when you have a lot of strings that have very many
unique values. In such a case the question is if all of these strings are
relatively short and have a similar size. If this is the case then you can use
the InlineStrings.jl package. It provides several types called String1,
String3, String7, String15 etc. where the number indicates maximum string
size in bytes that a given type can store. The benefit of these values is that
they are not heap allocated. It means that they are fast to work with and they
do not burden the Julia Garbage Collector.
Finally we are left with many strings, that have many unique values and that
have varying and possibly large size. In this case what Julia Base offers is a
sensible choice. Normally you should just use the String type stored in
standard collections like Vector. However, there is one special case when
you could consider using the Symbol type instead of a String type.
You can use Symbol instead of String if all the following conditions are
met:
- your strings are just labels that you only need to compare against each other;
in particular it assumes that you do not need to perform any transformations
on them; the reason is that
Symbolis not anAbstractStringso it cannot be passed to functions that only accept strings (as a benefit comparingSymbols is faster than comparingStrings); - you are OK with the fact that once
Symbolis created the memory it uses up will be never reclaimed by the Julia Garbage Collector until the end of the session (however, the benefit is that if you have several identicalSymbols they share the same memory).
Conclusions
Choosing an appropriate type to store your strings is often a quite hard decision. I hope that after reading this post you have a better overview of available options and when each of them is appropriate to be used.
It is also recommended to immediately convert the data to an appropriate format
when you read it in. Therefore, e.g. I recommend you to check out the
documentation of the CSV.jl package to learn how to specify what you
want to get when reading the CSV files (the most important keyword arguments
for handling these choices are pool and stringtype).